
In November last year, I gave a talk 1 at the DevOps Enterprise Summit in San Francisco.
A core point of my talk was that it’s time we start taking human performance seriously in the field of software engineering and operations:
“The increasing significance of our systems, the increasing potential for economic, political, and human damage when they don’t work properly, the proliferation of dependencies and associated uncertainty — all make me very worried. And, if you look at your own system and its problems, I think you will agree that we need to do more than just acknowledge this — we need to embrace it.”
This is not a hyperbolic statement. Consider the following list of events. Many (if not all) resulted in millions of dollars of loss – one bankrupted the company at close to half a billion dollar loss. Others put hospital patients, medical practitioners, and flight crews at greater risk. All of them resulted in many different cascading and second-order consequences, and in some cases took weeks or even months to resolve:
- Knight Capital, August 2012
- AWS, October 2012
- Medstar, April 2015
- NYSE, July 2015
- UAL, July 2015
- Facebook, September 2010
- GitHub, January 2016
- Southwest Airlines, July 2016
- Delta, August 2016
- SSP Pure broking, August 2016
This list is just a handful of serious software-centered accidents in recent history – I’m sure readers know of many others.
It’s not simply that the stakes are getting higher and that we have to understand how incidents and accidents like these happen in deeper ways. It’s also that we do not have a good understanding of how these sorts of events don’t happen more often than they do.
What Does It Mean To Take Human Performance Seriously?
As David Woods has plainly put it:
“If you haven’t found the people responsible for outcomes, you haven’t found ‘the system.'”
“Taking human performance seriously” means finding the people who are mired in the nitty-gritty of real work, and making a deliberate effort to explore and understand how they cope with the complexity that comes with working in modern software-reliant organizations.
Here’s the thing about real work: it’s messy. It’s continually filled with trade-offs, goal conflicts, time pressure, uncertainty, ambiguity, vague goals, high stakes, organizational constraints, and team coordination requirements.
Here’s another surprising thing about real work: engineers successfully (and for the most part, tacitly and invisibly!) – navigate all these challenges on a daily basis. In other words: the expertise and adaptive capacity of engineers is what keeps serious incidents from happening more often, and what keeps incidents from being more severe than they are. Therefore, understanding that expertise and adaptive capacity is critical if we have any hope of better supporting, amplifying, and extending it.
Now, you might say: “Of course! It’s all about the people!” – and you’d be right.
But not right in the way this aphorism is usually meant. A popular view in our industry is that challenges or issues can be seen as either:
- technical (as in the details of the technology, processes, practices, etc.)
- cultural (sometimes “social”, “ethical”, etc.)
- organizational (sometimes “management”, “governance”, etc.)
The notion that insight or solutions have to be seen through the lens of one of those perspectives is limiting. And while those topics are certainly interesting and important (and much has been written about them), I’m talking about something different.
I am asserting that we need to add another facet of how we understand our work: with a cognitive systems perspective. This means we need to introduce vocabulary and examples of what doing this look like.
You can see the Stella Report and my master’s thesis as first demonstrations of taking this view.
Taking a cognitive systems perspective
In the November talk, I presented a model of our world – a description of the context of software engineering and operations – to illustrate what I mean by “human performance.”
This is a short (6 minutes) but focused excerpt from the talk and explains where and how we need to direct our attention on human performance.
In other words, “taking human performance seriously” means discovering, exploring, and studying — very deliberately — the activities that happen “above the line.” It means contextualizing and making effort to understand how people do things such as:
- make decisions
- take actions
- solve problems
- repair misunderstandings
- continually re-calibrate and re-assess how their system(s) are behaving
- coordinate and cooperate with their colleagues (and their tools!)
Again, note that these activities always take place under conditions that have elements of uncertainty or ambiguity, and where mistakes can have significant consequences.
This is where we need to focus our attention because it’s been overlooked for far too long:
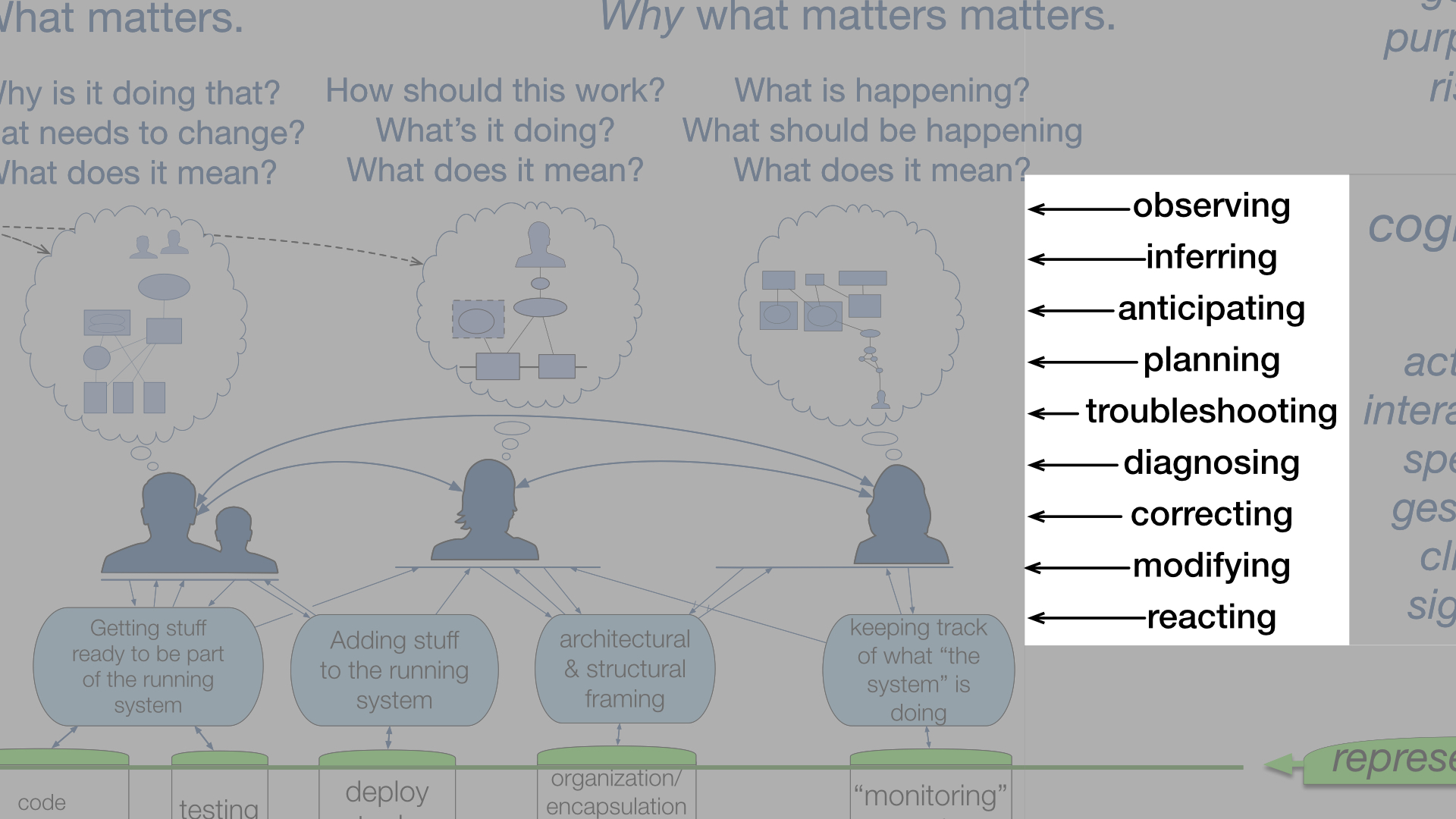
This is where work actually happens, and this is where we focus the work for our clients. We know how to explore, understand, and recalibrate what we find here for building resilience for companies.
Human performance, in this sense, is cognitive performance.
Cognition in the wild
Now, this perspective is not simply about psychology. While I am impressed that my community has been discovering past work on decision-making, it seems as if it’s solely centered around “cognitive biases” research, notably the work of Kahneman and Tversky.
In contrast to research around “cognitive biases,” whose methods “use pre-defined tasks given to naïve subjects under controlled laboratory conditions”, we need to make use of methods, approaches, and techniques to examine how cognitive work happens, in real-world situations2.
These come from the fields of Naturalistic Decision-Making, Cognitive Systems Engineering, and Resilience Engineering, and were developed to generate insights about how people cope with the real “messy details” so successfully, despite the complexity they face3.
This Is Only The Beginning
I have been focused on bringing these perspectives to the world of software for many years now. I’ve brought a number of people (see 4, 5, 6, 7, 8) who have spent their careers researching what happens “above the line” in many domains to speak at the Velocity Conference. I also received my master’s degree in Human Factors and Systems Safety, and helped put together the SNAFU Catchers consortium, alongside David Woods and Dr. Richard Cook.
For sure, there is a momentum building – more engineers are becoming curious about these topics. They’re sharing what they’re reading and they’re speaking about what they’re learning. Some are even diving even deeper by joining the same program I did (Nora Jones, Casey Rosenthal, Paul Reed, just to name a few…).
This is beyond encouraging to me – it’s an exciting time to witness this “bridging” of domains happening.
History has evidence about what happens when advances in technology outpace our understanding of people’s ability to cope with the complexity tech brings with it. In 1979, the Three-Mile Island disaster in brought a wake-up call to leaders in the field of human factors. The title of this post is a nod to a similar call for attention in the past9.
David Woods was very clear on this in 1990, roughly ten years after Three-Mile Island:
“A proper treatment of the human element requires the human to be the focus, where the technical plant provides the context in which we are interested in human performance. This means that there needs to be parallel efforts to understand the technical system–given humans are in the loop, and the human system–given the environment, demands and resources created by the technical system.”
In the early 2000s, incidents at NASA led the leading thinkers of Cognitive Systems Engineering to create the field of Resilience Engineering. Both events were pivotal moments – they demonstrated the crucial need to understand not just how accidents happen, but what critical roles people play in their prevention, containment, and resolution.
We cannot wait until software’s “Three-Mile Island” event to happen for our own wake-up call — we need to start now.
The future depends on taking human performance seriously in software, and this is why I’m focusing on it full-time.
- How Your Systems Keep Running Day After Day: Resilience Engineering as DevOps
- A seminal work on the importance of this is Cognition In The Wild, by Ed Hutchins. It is an extremely accessible book, highly recommended.
- Another accessible work on this is Sources of Power, by Gary Klein
- Dr. Richard Cook, Velocity 2012: “How Complex Systems Fail”
- Dr. Richard Cook, Velocity 2013 “Resilience in Complex Adaptive Systems”
- David Woods, Velocity 2014: “The Mystery of Sustained Adaptability”
- Johan Bergström, Velocity 2013: “What, Where And When Is Risk In System Design?”
- Steven Shorrock, Velocity 2014: “Life After Human Error”
- In 1990, a special issue of “Reliability Engineering and Systems Safety “On taking human performance seriously in risk analysis: Comments on Dougherty